





Fine-Grained Semi-Supervised Labeling of Large Shape Collections
We introduce a multi-label semi-supervised approach that takes as input a large shape collection of a given category with associated sparse and noisy labels, and outputs cleaned and complete labels for each shape. Experimental results show that this method outperforms state-of-the-art semi-supervised learning techniques.
Qi-xing Huang, Stanford University
Hao Su, Stanford University
Leonidas Guibas, Stanford University

Efficient Penetration Depth Approximation using Active Learning
Efficient PD approximation algorithm
Reliable PD computation based on translation and/or rotational motion
Interactive performance on non-convex and non-manifold rigid models
Jia Pan, University of North Carolina (UNC) Chapel Hill
Xinyu Zhang,University of North Carolina (UNC) Chapel Hill
Dinesh Manocha, University of North Carolina (UNC) Chapel Hill

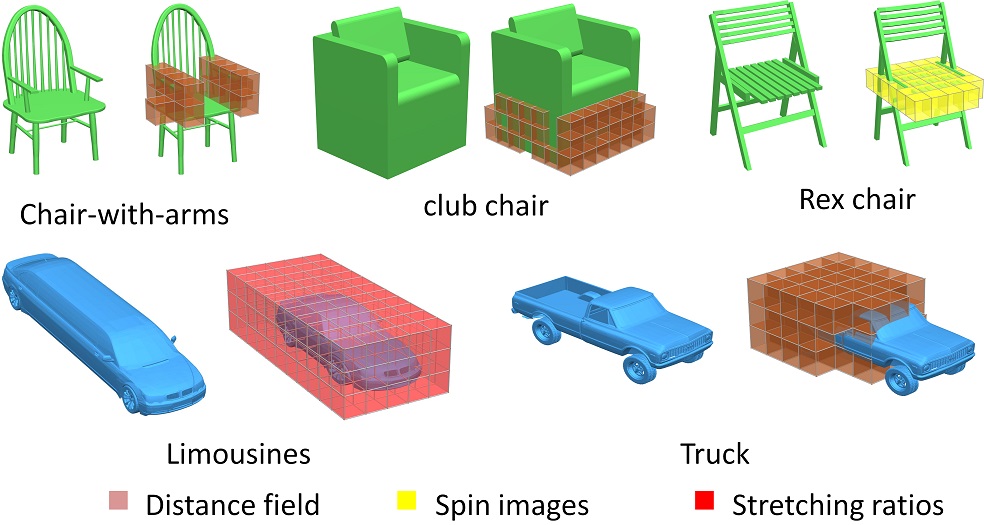
Projective Analysis for 3D Shape Segmentation
We introduce projective analysis for semantic segmentation and labelling of 3D shapes. The analysis treats an input 3D shape as a collection of 2D projections, labels each projection by transferring knowledge from existing labelled images, and back-projects and fuses the labellings on the 3D shape.
Yunhai Wang, Shenzhen Institute of Advanced Technology
Minglun Gong, Memorial University of Newfoundland
Tianhua Wang, Jilin University
Daniel Cohen-Or, Tel Aviv University
Hao Zhang, Simon Fraser University
Baoquan Chen, Shenzhen Institute of Advanced Technology
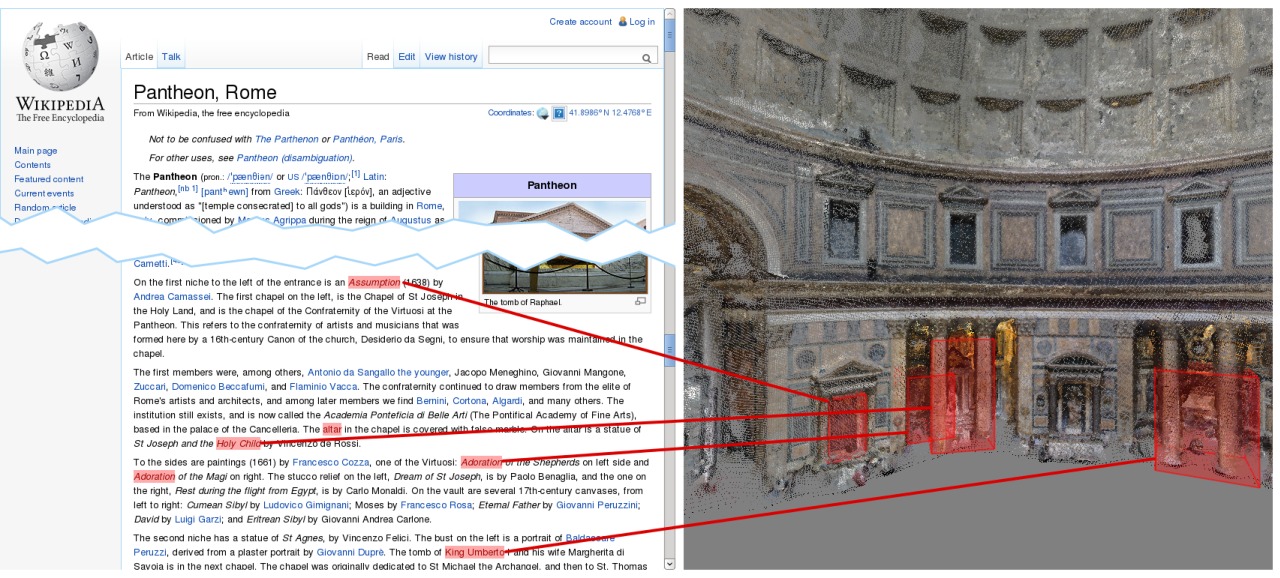
3D Wikipedia: Using online text to automatically label and navigate reconstructed geometry
Given a reference text, such as Wikipedia, and the site name, we automatically create a labeled 3D reconstruction, with objects in the model linked to where they appear in the text. Moreover, we have built a user interface that enables coordinated browsing of the text with the visualization
Bryan C. Russell, Intel Labs
Ricardo Martin-Brualla, University Of Washington
Daniel Butler, University Of Washington
Steve Seitz, University Of Washington
Luke Zettlemoyer, University Of Washington
Ricardo Martin-Brualla, University of Washington